
- Qwen2.5-Max is Alibaba’s latest AI model, positioned as a rival to GPT-4o, Claude 3.5 Sonnet, and DeepSeek V3.
- Unlike DeepSeek R1 and OpenAI’s o1, this model is not a reasoning AI, meaning it does not display its thought process.
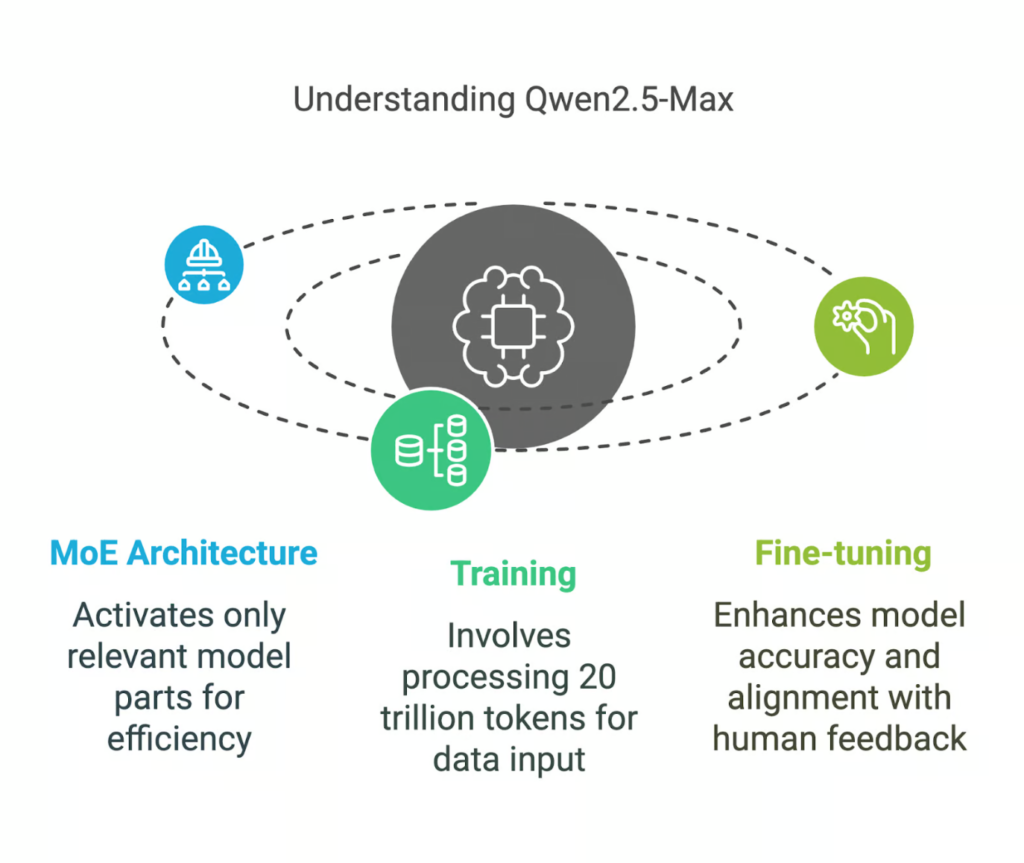
- Trained on 20 trillion tokens, Qwen2.5-Max employs a Mixture-of-Experts (MoE) architecture for greater efficiency and scalability.
- Benchmarks show Qwen2.5-Max outperforming DeepSeek V3 and Claude 3.5 Sonnet in key areas, including general knowledge, coding, and preference-based tasks.

What Is Qwen2.5-Max?
Qwen2.5-Max is Alibaba’s most powerful AI model to date, designed to compete with top-tier AI systems like GPT-4o, Claude 3.5 Sonnet, and DeepSeek V3.
Alibaba, primarily recognized for its e-commerce dominance, has made significant strides in cloud computing and artificial intelligence. The Qwen series is a core part of its AI expansion, encompassing both open-weight and proprietary models.
Unlike earlier Qwen models, Qwen2.5-Max is not open-source, meaning its internal architecture and parameters are not publicly available. Trained on an extensive 20 trillion tokens, this AI model boasts a broad knowledge base and exceptional general AI capabilities.
Although it lacks the explicit reasoning ability of DeepSeek R1 or OpenAI’s o1, Alibaba may introduce a dedicated reasoning model in future iterations, possibly with Qwen 3.
How Does Qwen2.5-Max Work?
Qwen2.5-Max is built using a Mixture-of-Experts (MoE) architecture, similar to DeepSeek V3. This design allows for scalable AI processing without excessive computational costs.
Understanding Mixture-of-Experts (MoE) Architecture
Unlike traditional models that activate all parameters for every input, MoE models selectively engage only the most relevant sections for specific tasks.
Imagine a team of specialists—if a question involves physics, only physics experts contribute while others remain idle. This efficient allocation of computational resources makes MoE-based models like Qwen2.5-Max both powerful and cost-effective compared to dense models like GPT-4o.
Training and Optimization
Qwen2.5-Max was trained on 20 trillion tokens, equivalent to roughly 15 trillion words. To put this into perspective, George Orwell’s 1984 contains 89,000 words, meaning this model was trained on the equivalent of 168 million copies of the book.
Alibaba further refined Qwen2.5-Max using:
- Supervised Fine-Tuning (SFT): Human experts curated high-quality responses to guide AI-generated answers.
- Reinforcement Learning from Human Feedback (RLHF): The model was trained to align responses with human preferences, improving natural language interaction.
Qwen2.5-Max vs. GPT-4o, Claude 3.5 Sonnet, Llama 3.1-405B, and DeepSeek V3: Which AI Model Reigns Supreme?
As AI models continue to evolve, Alibaba’s Qwen2.5-Max has entered the competitive landscape, directly challenging GPT-4o, Claude 3.5 Sonnet, Llama 3.1-405B, and DeepSeek V3. Each of these models has unique strengths and weaknesses, making them suitable for different use cases. Below, we compare their capabilities, performance, and limitations across key benchmarks and functionalities.
Comparison at a Glance
| AI Model | Best At | Weaknesses | Primary Use Case |
|---|---|---|---|
| Qwen2.5-Max | General AI tasks, efficiency | Not as strong in reasoning as DeepSeek R1 | Large-scale AI applications, enterprise solutions |
| GPT-4o | Language fluency, deep knowledge | High computational cost | Conversational AI, creative content |
| Claude 3.5 Sonnet | Natural language understanding | Slightly weaker in factual recall | Business & enterprise applications |
| DeepSeek V3 | Cost-efficiency, MoE scalability | Lower accuracy on certain benchmarks | AI model efficiency, research |
| Llama 3.1-405B | Open-source accessibility | Lacks full-scale optimization | Custom AI development, experimental models |
Key Similarities Across All Models
- All models leverage large-scale training datasets to improve natural language processing and reasoning.
- They all support multiple languages and have varying degrees of fluency across different linguistic structures.
- Each model employs deep learning optimizations, with some focusing on efficiency (DeepSeek V3, Qwen2.5-Max) while others prioritize accuracy (GPT-4o, Claude 3.5 Sonnet).
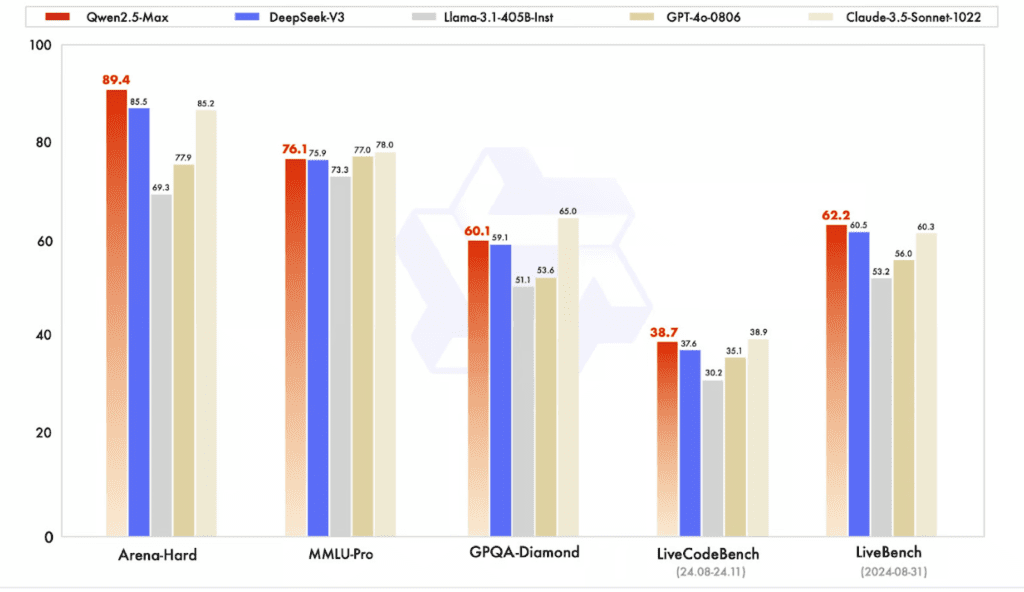
Performance Benchmark Comparison
| Benchmark | Qwen2.5-Max | GPT-4o | Claude 3.5 Sonnet | DeepSeek V3 | Llama 3.1-405B |
|---|---|---|---|---|---|
| Language Fluency (Arena-Hard) | 89.4 | 92.1 | 85.2 | 85.5 | 81.3 |
| Knowledge & Reasoning (MMLU-Pro) | 76.1 | 77.0 | 78.0 | 75.9 | 72.5 |
| General Knowledge QA (GPQA-Diamond) | 60.1 | 58.5 | 65.0 | 59.1 | 55.7 |
| Coding Ability (LiveCodeBench) | 38.7 | 41.5 | 38.9 | 37.6 | 34.9 |
| Mathematical Problem Solving (GSM8K) | 94.5 | 93.7 | 91.2 | 89.3 | 89.0 |
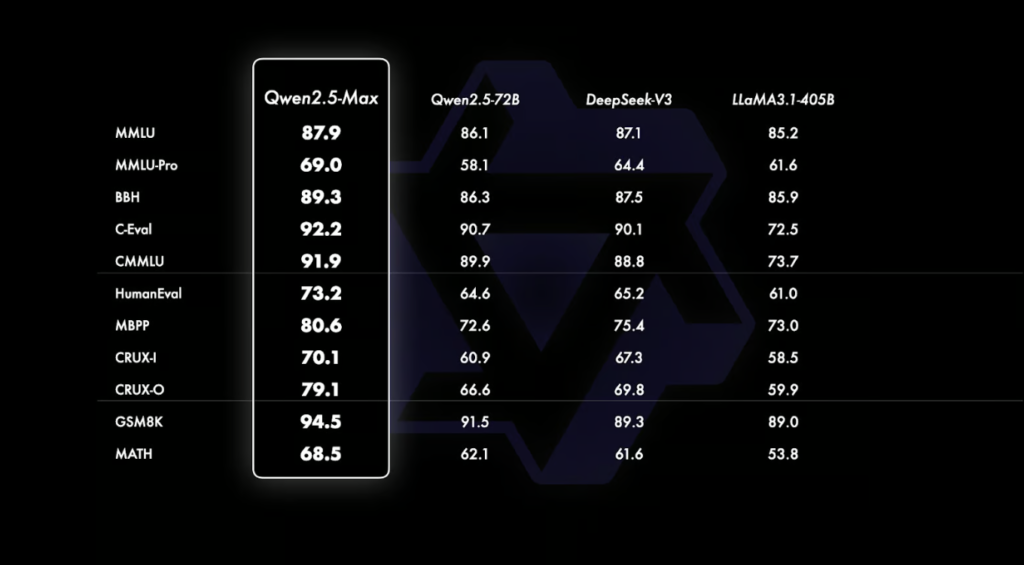
Key Observations:
- GPT-4o remains the most fluent model, especially in natural language understanding and human-like conversation.
- Claude 3.5 Sonnet outperforms others in factual knowledge and reasoning-based benchmarks.
- Qwen2.5-Max leads in mathematical problem-solving and overall efficiency, benefiting from Alibaba’s optimized AI processing.
- DeepSeek V3 is an excellent cost-efficient model, though it lags slightly behind in general reasoning.
- Llama 3.1-405B, while open-source, struggles against proprietary models in several key benchmarks.
Strengths & Weaknesses Breakdown
| AI Model | Strengths | Weaknesses |
|---|---|---|
| Qwen2.5-Max (Alibaba) | – Excels in general AI tasks and enterprise solutions – Uses Mixture-of-Experts (MoE) architecture, enhancing efficiency – Strong mathematical reasoning capabilities | – Lacks explicit reasoning capabilities, unlike DeepSeek R1 – Not open-source, limiting accessibility |
| GPT-4o (OpenAI) | – Best-in-class language fluency and conversational AI – High accuracy in complex reasoning and deep knowledge tasks – Strong coding and problem-solving skills | – High computational cost, making it less efficient than Qwen2.5-Max or DeepSeek V3 – Not optimized for cost-conscious deployments |
| Claude 3.5 Sonnet (Anthropic) | – Best at factual recall and general knowledge – Performs well in ethics-based and safe AI outputs – Balanced efficiency and performance | – Slightly weaker in mathematical and coding benchmarks – Does not match GPT-4o in fluency |
| DeepSeek V3 (DeepSeek) | – Highly cost-effective, making it a strong competitor to larger models – Uses MoE architecture, reducing GPU usage – Encourages open-source AI innovation | – Lower accuracy in complex reasoning tasks – Limited global adoption compared to OpenAI models |
| Llama 3.1-405B (Meta) | – Open-source, making it adaptable for researchers – Good performance in general AI applications | – Weaker performance in math and coding compared to GPT-4o or Claude 3.5 Sonnet – Lacks full-scale optimization for real-world applications |
Alibaba’s Qwen2.5-Max is a major step forward, especially in mathematical reasoning and AI efficiency. While GPT-4o and Claude 3.5 Sonnet remain top choices for conversational AI and factual reasoning, Qwen2.5-Max excels in computational efficiency and enterprise applications.
Meanwhile, DeepSeek V3 is proving to be a disruptive force by offering high-quality AI performance at a fraction of the cost. Llama 3.1-405B remains an excellent choice for open-source AI development, but its limitations in performance make it less competitive against proprietary models.
Which AI Model Should You Choose?
| If you want… | Best AI Model |
|---|---|
| Best natural language fluency | GPT-4o |
| Strongest reasoning and factual recall | Claude 3.5 Sonnet |
| Most cost-efficient and scalable model | DeepSeek V3 |
| Best for mathematical and problem-solving tasks | Qwen2.5-Max |
| An open-source alternative for research | Llama 3.1-405B |
How to Access Qwen2.5-Max
Alibaba offers multiple ways for users to interact with Qwen2.5-Max:
1. Qwen Chat (Web-Based AI Assistant)
Users can try Qwen2.5-Max for free on Qwen Chat, a web-based platform similar to ChatGPT. Simply select Qwen2.5-Max from the model dropdown to begin using it.
2. API Access via Alibaba Cloud
For developers, Qwen2.5-Max is accessible via the Alibaba Cloud Model Studio API.
- Users must sign up for an Alibaba Cloud account, activate Model Studio, and generate an API key.
- The API format mirrors OpenAI’s, making integration straightforward for developers already familiar with OpenAI models.
For step-by-step API setup, refer to Alibaba Cloud’s official Qwen2.5-Max documentation.
Conclusion
Qwen2.5-Max represents Alibaba’s strongest AI model to date, designed to compete with global leaders like GPT-4o, Claude 3.5 Sonnet, and DeepSeek V3.
While it lacks explicit reasoning capabilities like DeepSeek R1, its powerful MoE architecture, extensive training data, and superior benchmark performance make it a formidable player in the AI space.
With continued AI investment, it’s likely Alibaba will release a reasoning-based Qwen model in the near future—potentially Qwen 3.
Related articles:
What Is DeepSeek and Why Is It Crashing AI Stocks?
DeepSeek shows how Trump tariffs doomed to fail
DeepSeek Causes $1 Trillion Drop in Tech Stocks
Why market panic over China’s DeepSeek is ‘overblown,’ analysts say
DeepSeek ban coming soon? White House “looking into” national security implications of it
CEO of Scale AI Says DeepSeek is Lying to Everyone
Main Source: DataCamp







